
Time series analysis is a specialized statistical technique used to analyze data points collected at consistent intervals over a defined period. Unlike datasets gathered sporadically or arbitrarily, time series data focuses on observations made at regular time steps, allowing analysts to identify patterns, trends, and seasonal variations within the data.
Essentially, this method involves examining clearly defined data points generated through continuous and systematic measurement. For instance, a time series might represent monthly retail sales figures or daily temperature readings. In this tutorial, we will explore various time series techniques using the R programming language.
Stock price prediction serves as a practical example of time series forecasting. It involves estimating the future value of an individual stock, a specific market sector, or an entire market index. In this study, we will apply several forecasting methods, including the Naive approach, Simple Exponential Smoothing, ARIMA, and Holt’s Trend Model. When the dataset exhibits seasonal fluctuations, advanced models such as Seasonal Naive or TBATS can be employed to improve forecasting accuracy.
To demonstrate these techniques, we will use Apple Inc.’s stock price data obtained from Yahoo Finance. The dataset spans approximately 22 years of monthly closing prices, comprising 264 observations across six variables. For this univariate time series analysis, only the closing price variable is utilized, as it provides a reliable indicator for forecasting the subsequent period’s opening price.
library(readxl)
library(urca)
library(lmtest)
library(fpp2)
library(forecast)
library(TTR)
library(dplyr)
library(tseries)
library(aTSA)AAPL = read_excel("/file_path/AAPL.xlsx")
str(AAPL) # To check the structure of the dataframe Before building any predictive model, it’s essential to split the dataset into training and testing sets. Typically, around 80% of the data is allocated for training the model, while the remaining 20% is reserved for testing its performance and accuracy.
class = c(rep("TRAIN", 211), rep("TEST",53)) # creating the TRAIN and TEST as class varible
str(class)
AAPL = cbind(AAPL, class) # Binding the "class" column with the existing AAPL data frame
AAPL
# Splitting the data
train_data = subset(AAPL, class == 'TRAIN')
test_data = subset(AAPL, class == 'TEST')
dat_ts = ts(train_data[,5], start = c(2000,1), end = c(2017,07), frequency = 12)
dat_ts mae = function(actual,pred){
mae = mean(abs(actual - pred))
return (mae)
}
RMSE = function(actual,pred){
RMSE = sqrt(mean((actual - pred)^2))
return (RMSE)
}Forecasting models:
Navie Model
nav = naive(dat_ts, h = 53)
summary(nav)
df_nav = as.data.frame(nav)
mae(test_data$Close, df_nav$`Point Forecast`)
RMSE(test_data$Close, df_nav$`Point Forecast`)

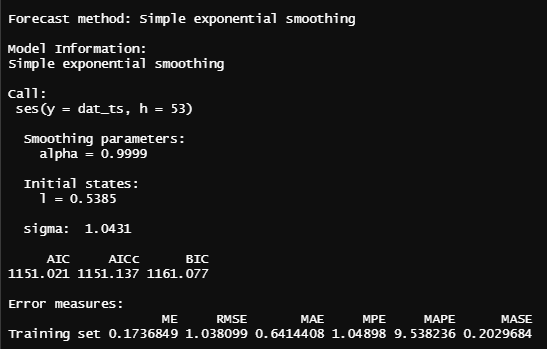
Simple Exponential Smoothing
se_model = ses(dat_ts, h = 53)
summary(se_model)
###
df_s = as.data.frame(se_model)
mae(test_data$Close, df_s$`Point Forecast`)
RMSE(test_data$Close, df_s$`Point Forecast`)

Holt's Trend Method
holt_model = holt(dat_ts, h = 53)
summary(holt_model)
####
df_h = as.data.frame(holt_model)
mae(test_data$Close, df_h$`Point Forecast`)
RMSE(test_data$Close, df_h$`Point Forecast`)


ARIMA
auto.arima() function in R programming automatically selects the best model parameters by evaluating multiple combinations and choosing the one with the lowest Akaike Information Criterion (AIC) value, ensuring the most efficient fit for the data. In the R code example provided below, we demonstrate how to use the auto.arima() function to build a reliable forecasting model that adapts to the time series’ structure. This method not only enhances forecast precision but also serves as a benchmark for evaluating the performance of other advanced forecasting techniques.arima_model_AIC = auto.arima(dat_ts,stationary = FALSE, seasonal = FALSE, ic = "aic", stepwise = TRUE, trace = TRUE)
summary(arima_model_AIC)
###
fore_arima = forecast::forecast(arima_model_AIC, h=53)
df_arima = as.data.frame(fore_arima)
df_arima
mae(test_data$Close, df_arima$`Point Forecast`)
RMSE(test_data$Close, df_arima$`Point Forecast`)

par(mfrow=c(2,2))
plot(nav)
plot(se_model)
plot(holt_model)
plot(fore_arima)

Conclusion
|
METHODS |
MAE |
RMSE |
|
Naive Method |
43.46 |
59.85 |
|
Simple Exponential Smoothing |
43.46 |
59.85 |
|
Holt’s Trend Method |
38.83 |
54.82 |
|
ARIMA |
39.33 |
55.23 |
Post a Comment
The more questions you ask, the more comprehensive the answer becomes. What would you like to know?